📖 この記事で分かること
・NotebookLMが手書きメモや図表を読み取れるようになった
・写真を撮るだけで音声解説やレポートが自動生成される
・学生から研究者まで、あなたの勉強スタイルが変わる
・実際にどんな画像が使えるのか、具体例で分かる
💡 知っておきたい用語
・OCR【オーシーアール】:手書きや印刷文字を読み取ってデジタル文字に変換する技術
最終更新日: 2025年11月16日
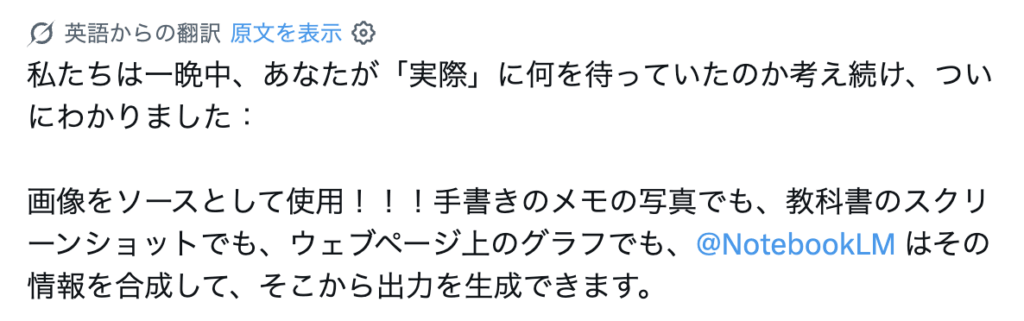
先日まで「一晩中何を待っているのか分からなかった」というNotebookLMチームの謎めいた投稿に、多くのユーザーが首をかしげていました。でも、その答えがついに発表されました。[1]
想像以上の認識精度を実現
NotebookLMに画像ソース機能が追加されたのです。手書きのメモ、教科書のスクリーンショット、ウェブページの図表など、写真として撮影した画像をアップロードするだけで、その内容を理解して音声解説やレポートを生成してくれます。[2]
実に興味深いのは、この機能が単純な文字認識(OCR)を超えている点です。ただ文字を読み取るだけでなく、画像に含まれる情報全体を「理解」して、それを元に新しいコンテンツを生成する、いわゆるマルチモーダルAI【エーアイ】の実現です。
マルチモーダルAIとは、テキスト、画像、音声など複数の形式のデータを同時に処理できるAI技術のことです。技術的には、画像認識モデルと大規模言語モデルを組み合わせ、視覚情報と言語理解を統合することで、人間に近い包括的な理解を可能にしています。
実際に試すとこんな感じです。
ベゾス(Amazon)の有名な手描きの成長ループ(フライホイール)を読み込んだ状態がこちらです。
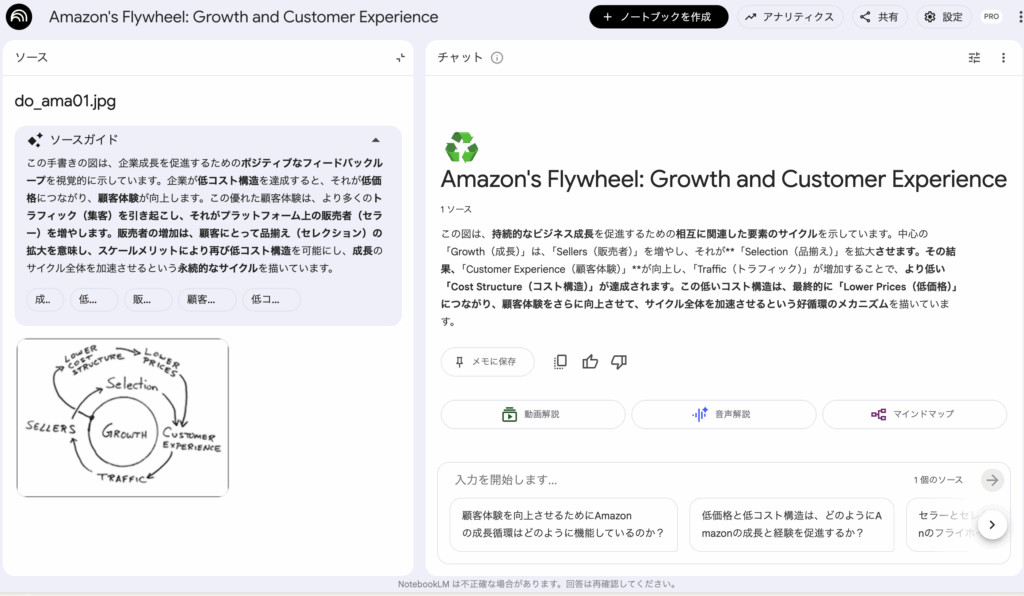
※ 余談ですが、現在、当時の手描きの成長ループ(フライホイール)の掲載は確認できませんでした。
ベゾスの成長ループ原典とは別物ですが、AWS公式では「Comprehend flywheel」などサービス別のフライホイール解説があります。
こちら:https://aws.amazon.com/jp/blogs/machine-learning/introducing-the-amazon-comprehend-flywheel-for-mlops/
開発者も驚く活用シーン
正直なところ、この機能の登場は多くの開発者にとっても驚きでした。なぜなら、画像から情報を抽出してそれを音声コンテンツに変換するまでの技術的ハードルは、想像以上に高いからです。
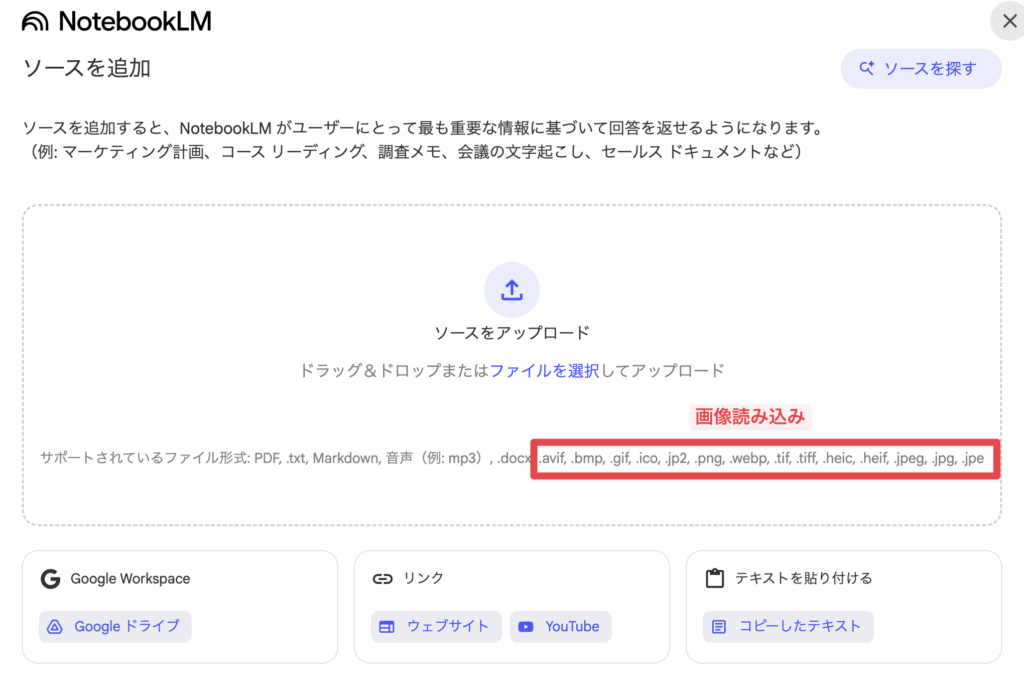
対応している画像形式は以下の通りです:
- 手書きメモ: 授業ノート、会議メモ、アイデアスケッチ
- スクリーンショット: 教科書、プレゼン資料、ウェブページ
- 図表・グラフ: データ可視化、統計資料、技術図面
これって実は、学生だけの話じゃないんです。エンジニアなら、ホワイトボードに描いたアーキテクチャ図を撮影してドキュメント化したり、手書きのアルゴリズム設計をそのまま技術解説に変換したり。営業の方なら、手書きの顧客ヒアリングメモから提案書のベースを作ったり。
技術的な仕組みと可能性
開発現場では、OCR技術の精度向上が長年の課題でした。特に手書き文字の認識は、個人の筆跡の違いや文字のかすれ、背景ノイズなどで精度が大きく左下がることがありました。
でも、NotebookLMのこの機能は、単純な文字認識を超えています。画像全体の文脈を理解し、図表の関係性も把握して、それらを統合したコンテンツを生成する。これは、Google【グーグル】のVision API【エーピーアイ】の技術進歩と、Geminiモデルの言語理解能力が組み合わさった結果と考えられます。
注目すべき点は、この機能が教育分野に与えるインパクトです。学生が授業ノートを撮影するだけで、その内容を元にした音声解説が生成される。これにより、復習の効率が劇的に向上する可能性があります。
今後の展開と期待
個人的には、この機能の登場で「情報のデジタル化」という概念が大きく変わると感じています。これまでは、紙の資料をデジタル化するには手作業での入力やスキャンが必要でした。でも今後は、写真を撮るだけでAIが内容を理解し、さまざまな形式で再生成してくれる時代になります。
ビジネス活用の観点では、以下のような展開が期待されます:
- 教育: 手書きノートから個人向け学習コンテンツの自動生成
- 研究: 図表やデータから研究レポートの下書き作成
- 企業: 会議のホワイトボードから議事録や提案書の作成
ただ、気をつけたいのは、AI生成コンテンツの精度です。特に専門的な内容や複雑な図表については、生成された内容の確認と修正が必要になるでしょう。これは技術的な限界というより、責任ある活用のための必要なプロセスです。
よくある質問
Q: どんな画像ファイル形式に対応していますか?
A: 一般的なJPEG、PNG形式の画像に対応しています。スマートフォンで撮影した写真であれば基本的に利用可能です。
Q: 手書き文字の認識精度はどの程度ですか?
A: 明瞭に書かれた文字であれば高い精度で認識されますが、読みにくい文字や複雑な図については、生成されたコンテンツの確認が推奨されます。
Q: 日本語の手書きメモにも対応していますか?
A: はい、日本語を含む多言語の手書きテキストに対応していると予想されます。ただし、実際の精度は使用してみて確認することをお勧めします。
まとめ
NotebookLMの画像ソース機能は、単なる新機能の追加を超えて、私たちの情報管理と学習方法を根本的に変える可能性を秘めています。手書きメモから音声解説への変換は、デジタルとアナログの境界を曖昧にし、より直感的で効率的な知識活用を実現します。
この機能をいち早く試して、あなたの学習や業務にどう活用できるか探ってみてはいかがでしょうか。
【用語解説】
- OCR【オーシーアール】: Optical Character Recognitionの略で、画像内の文字を読み取ってデジタルテキストに変換する技術
- マルチモーダルAI【エーアイ】: テキスト、画像、音声などの複数のデータ形式を同時に処理できる人工知能
- Vision API【エーピーアイ】: Googleが提供する画像解析サービス。Application Programming Interfaceの略で、ソフトウェア同士が情報をやり取りするための窓口のような仕組み
- Gemini【ジェミニ】: Googleが開発した大規模言語モデル。テキスト理解と生成に特化したAI技術
免責事項: 本記事の情報は執筆時点のものです。必ず最新情報をご確認ください。AI技術は急速に進歩しているため、機能や制限は予告なく変更される場合があります。
Citations:
[1] https://x.com/NotebookLM/status/1989392074119020981
[2] https://blockchain.news/ainews/notebooklm-launches-image-to-text-ai-transforming-photos-and-screenshots-into-actionable-insights
[3]https://www.reddit.com/r/aicuriosity/comments/1ox4mma/notebooklm_update_using_images_as_sources_for_ai/
[4] https://www.reddit.com/r/AICompanions/comments/1ox5zml/images_as_sources/